Prediction Housing Prices in Iowa. Exploratory Data Analysis, Dealing with Missing Values, Data Munging, Ensembled Regression Model using Stacked Regressor, XGBoost and microsoft LightGBM
Currently in top 5% (143rd in 1890 participants), Last ran on: July 1st, 2017
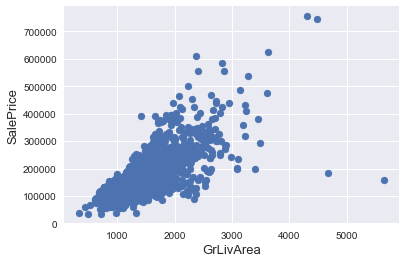
Documentation for the Ames Housing Data indicates that there are outliers present in the training data 1: http://ww2.amstat.org/publications/jse/v19n3/Decock/DataDocumentation.txt
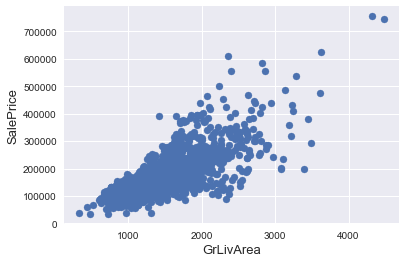
We can see at the bottom right two with extremely large GrLivArea that are of a low price. These values are huge oultliers. Therefore, we can safely delete them.
Note :
Outliers removal is not always safe. We decided to delete these two as they are very huge and really bad ( extremely large areas for very low prices).
There are probably others outliers in the training data. However, removing all them may affect badly our models if ever there were also outliers in the test data. That’s why , instead of removing them all, we will just manage to make some of our models robust on them. You can refer to the modelling part of this notebook for that.
Target Variable
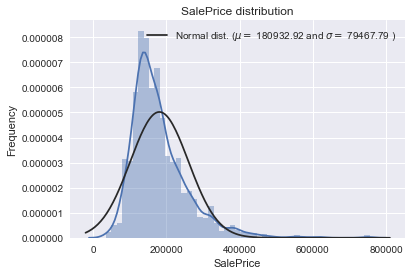
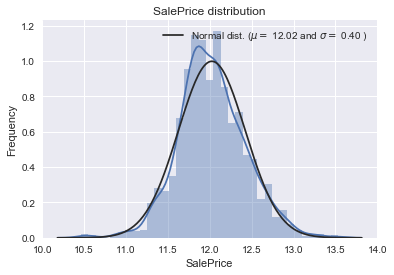
SalePrice is the variable we need to predict. So let’s do some analysis on this variable first.
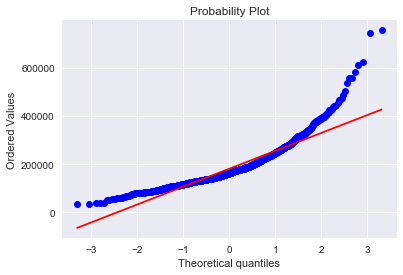
The target variable is right skewed. As (linear) models love normally distributed data , we need to transform this variable and make it more normally distributed.
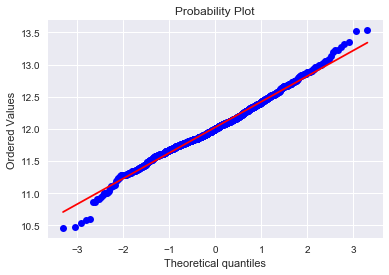
Log-transformation of the target variable
The skew seems now corrected and the data appears more normally distributed.
Features engineering
let’s first concatenate the train and test data in the same dataframe
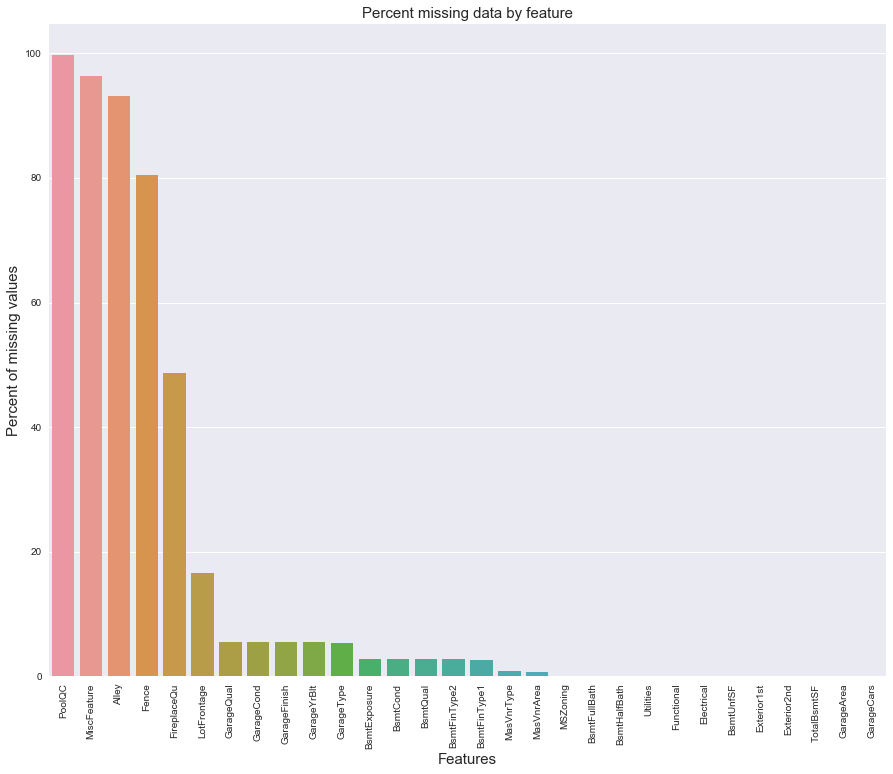
Missing Data
Missing Ratio
PoolQC
99.691
MiscFeature
96.400
Alley
93.212
Fence
80.425
FireplaceQu
48.680
LotFrontage
16.661
GarageQual
5.451
GarageCond
5.451
GarageFinish
5.451
GarageYrBlt
5.451
GarageType
5.382
BsmtExposure
2.811
BsmtCond
2.811
BsmtQual
2.777
BsmtFinType2
2.743
BsmtFinType1
2.708
MasVnrType
0.823
MasVnrArea
0.788
MSZoning
0.137
BsmtFullBath
0.069
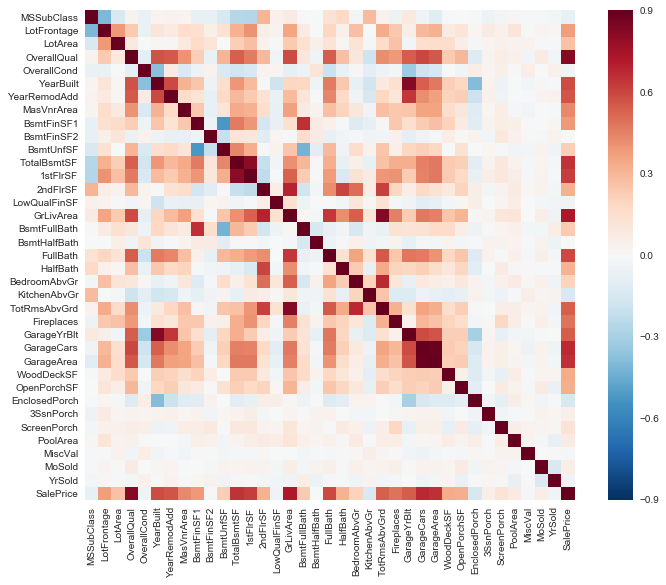
Data Correlation
Imputing missing values
We impute them by proceeding sequentially through features with missing values
PoolQC : data description says NA means “No Pool”. That make sense, given the huge ratio of missing value (+99%) and majority of houses have no Pool at all in general.
LotFrontage : Since the area of each street connected to the house property most likely have a similar area to other houses in its neighborhood , we can fill in missing values by the median LotFrontage of the neighborhood.
#Group by neighborhood and fill in missing value by the median LotFrontage of all the neighborhoodall_data["LotFrontage"]=all_data.groupby("Neighborhood")["LotFrontage"].transform(lambdax:x.fillna(x.median()))
GarageType, GarageFinish, GarageQual and GarageCond : Replacing missing data with None
BsmtQual, BsmtCond, BsmtExposure, BsmtFinType1 and BsmtFinType2 : For all these categorical basement-related features, NaN means that there is no basement.
Utilities : For this categorical feature all records are “AllPub”, except for one “NoSeWa” and 2 NA . Since the house with ‘NoSewa’ is in the training set, this feature won’t help in predictive modelling. We can then safely remove it.
all_data=all_data.drop(['Utilities'],axis=1)
Functional : data description says NA means typical
Transforming some numerical variables that are really categorical
Label Encoding some categorical variables that may contain information in their ordering set
Adding one more important feature
Since area related features are very important to determine house prices, we add one more feature which is the total area of basement, first and second floor areas of each house
Skewed features
Skew
MiscVal
21.940
PoolArea
17.689
LotArea
13.109
LowQualFinSF
12.085
3SsnPorch
11.372
LandSlope
4.973
KitchenAbvGr
4.301
BsmtFinSF2
4.145
EnclosedPorch
4.002
ScreenPorch
3.945
Box Cox Transformation of (highly) skewed features
We use the scipy function boxcox1p which computes the Box-Cox transformation of \(1 + x\).
Note that setting \( \lambda = 0 \) is equivalent to log1p used above for the target variable.
See this page for more details on Box Cox Transformation as well as [the scipy function’s page]2: http://onlinestatbook.com/2/transformations/box-cox.html [2]: https://docs.scipy.org/doc/scipy-0.19.0/reference/generated/scipy.special.boxcox1p.html
There are 59 skewed numerical features to Box Cox transform
Modelling
In this approach, we add a meta-model on averaged base models and use the out-of-folds predictions of these base models to train our meta-model.
The procedure, for the training part, may be described as follows:
Split the total training set into two disjoint sets (here train and .holdout )
Train several base models on the first part (train)
Test these base models on the second part (holdout)
Use the predictions from 3) (called out-of-folds predictions) as the inputs, and the correct responses (target variable) as the outputs to train a higher level learner called meta-model.
The first three steps are done iteratively . If we take for example a 5-fold stacking , we first split the training data into 5 folds. Then we will do 5 iterations. In each iteration, we train every base model on 4 folds and predict on the remaining fold (holdout fold).
So, we will be sure, after 5 iterations , that the entire data is used to get out-of-folds predictions that we will then use as new feature to train our meta-model in the step 4.
For the prediction part , We average the predictions of all base models on the test data and used them as meta-features on which, the final prediction is done with the meta-model.
On this gif, the base models are algorithms 0, 1, 2 and the meta-model is algorithm 3. The entire training dataset is A+B (target variable y known) that we can split into train part (A) and holdout part (B). And the test dataset is C.
B1 (which is the prediction from the holdout part) is the new feature used to train the meta-model 3 and C1 (which is the prediction from the test dataset) is the meta-feature on which the final prediction is done.
Define a cross validation strategy
We use the cross_val_score function of Sklearn. However this function has not a shuffle attribut, we add then one line of code, in order to shuffle the dataset prior to cross-validation
Base models
LASSO Regression :
This model may be very sensitive to outliers. So we need to made it more robust on them. For that we use the sklearn’s Robustscaler() method on pipeline
Simplest Stacking approach : Averaging base models
We begin with this simple approach of averaging base models. We build a new class to extend scikit-learn with our model and also to laverage encapsulation and code reuse (inheritance)
Averaged base models class
classAveragingModels(BaseEstimator,RegressorMixin,TransformerMixin):def__init__(self,models):self.models=models# we define clones of the original models to fit the data indeffit(self,X,y):self.models_=[clone(x)forxinself.models]# Train cloned base modelsformodelinself.models_:model.fit(X,y)returnself#Now we do the predictions for cloned models and average themdefpredict(self,X):predictions=np.column_stack([model.predict(X)formodelinself.models_])returnnp.mean(predictions,axis=1)
Averaged base models score
We just average four models here ENet, GBoost, KRR and lasso. Of course we could easily add more models in the mix.
averaged_models=AveragingModels(models=(ENet,GBoost,KRR,lasso))score=rmsle_cv(averaged_models)print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(),score.std()))
class="highlight">
1
Averaged base models score: 0.1091 (0.0075)
Wow ! It seems even the simplest stacking approach really improve the score . This encourages us to go further and explore a less simple stacking approch.
Less simple Stacking : Adding a Meta-model
Stacking averaged Models Class
classStackingAveragedModels(BaseEstimator,RegressorMixin,TransformerMixin):def__init__(self,base_models,meta_model,n_folds=5):self.base_models=base_modelsself.meta_model=meta_modelself.n_folds=n_folds# We again fit the data on clones of the original modelsdeffit(self,X,y):self.base_models_=[list()forxinself.base_models]self.meta_model_=clone(self.meta_model)kfold=KFold(n_splits=self.n_folds,shuffle=True,random_state=156)# Train cloned base models then create out-of-fold predictions# that are needed to train the cloned meta-modelout_of_fold_predictions=np.zeros((X.shape[0],len(self.base_models)))fori,modelinenumerate(self.base_models):fortrain_index,holdout_indexinkfold.split(X,y):instance=clone(model)self.base_models_[i].append(instance)instance.fit(X[train_index],y[train_index])y_pred=instance.predict(X[holdout_index])out_of_fold_predictions[holdout_index,i]=y_pred# Now train the cloned meta-model using the out-of-fold predictions as new featureself.meta_model_.fit(out_of_fold_predictions,y)returnself#Do the predictions of all base models on the test data and use the averaged predictions as #meta-features for the final prediction which is done by the meta-modeldefpredict(self,X):meta_features=np.column_stack([np.column_stack([model.predict(X)formodelinbase_models]).mean(axis=1)forbase_modelsinself.base_models_])returnself.meta_model_.predict(meta_features)
Stacking Averaged models Score
To make the two approaches comparable (by using the same number of models) , we just average Enet KRR and Gboost, then we add lasso as meta-model.
'''RMSE on the entire Train data when averaging'''print('RMSLE score on train data:')print(rmsle(y_train,stacked_train_pred*0.70+xgb_train_pred*0.15+lgb_train_pred*0.15))